
A team spanning Google DeepMind and UMass-Amherst's Reich Lab has published a prospective study showing that an autonomous LLM-guided tree search can generate epidemiological forecasting models as executable code and submit them to official CDC forecast hubs in real time during the 2025–2026 disease season. The paper, titled "Prospective multi-pathogen disease forecasting using autonomous LLM-guided tree search" (arXiv 2605.16238), is authored by Sarah Martinson, Michael P. Brenner, Martyna Plomecka, Brian P. Williams, Nicholas G. Reich, and Zahra Shamsi. Weekly submissions competed directly against the CDC-coordinated ensemble and established human-built entries across both the FluSight and COVID-19 forecast hubs.
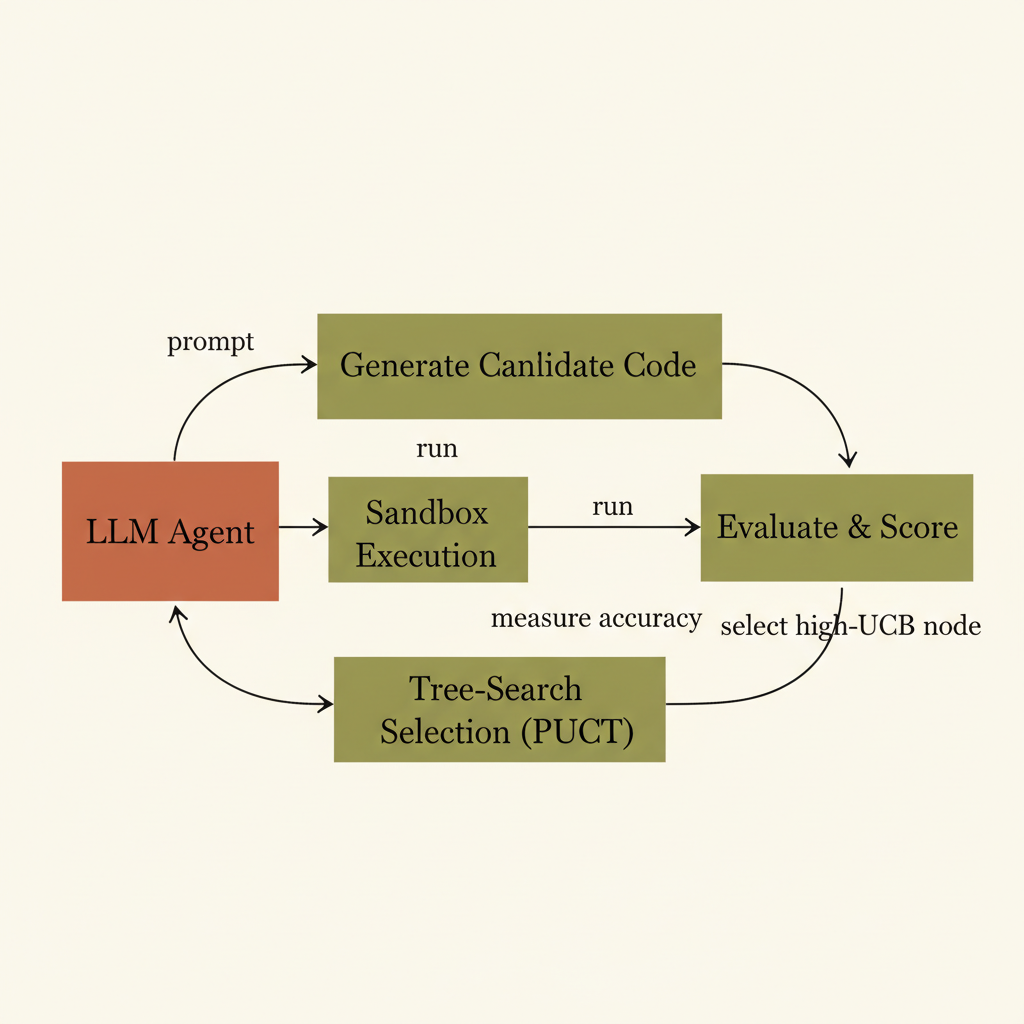
The architecture descends from a foundational system described in arXiv 2509.06503, with Shamsi as a shared author. The core loop has three components: an LLM acting as a code mutation engine, a PUCT-variant tree search governing which candidate nodes to expand based on empirical score and exploration bonus, and a sandbox executor that runs each candidate model and returns a numeric quality score. No human curates mutations between iterations. The system can ingest external literature and inject method summaries as prompts, synthesizing hybrids of published approaches that no individual prior paper described. The evaluation metric is defined at the start — a proper scoring rule matching whichever CDC hub the submission targets — so the reward signal the LLM receives matches the official leaderboard ranking.
In retrospective benchmarks, the foundational system generated 14 distinct models that each outperformed the CDC ensemble for COVID-19 hospitalization forecasting. In genomics, 40 of 87 generated methods exceeded the top human-developed entry on the OpenProblems v2.0.0 leaderboard for single-cell RNA-seq batch integration. One method recombined ComBat and BBKNN and yielded a 14% improvement over the prior best result. This paper eliminates the retrospective escape hatch by submitting weekly to a blinded, time-stamped leaderboard during a live season, preventing implicit overfitting to historical outcome patterns.

The agent produces Python code, not latent embeddings or weight files. Every tree-search node is runnable software that generates the forecast. Production epidemiology teams can diff, inspect, and compose these models. When the search discovers a hybrid approach that outperforms both parents, the result is legible software that public health analysts can audit. Submissions land in publicly archived CDC forecast hub repositories, providing a permanent, reproducible audit trail.
Compute budget, cost per forecast cycle, wall-clock latency per tree-search run, and the LLM(s) used as the code mutation engine are not disclosed in either this paper or its predecessor. The mutation loop runs on API calls rather than specialized inference hardware; sandbox evaluation is CPU-bound. Cost contours remain unknown for teams considering adoption.
The hardest unsolved problem is distribution shift within a live season. The tree search's feedback loop depends on CDC hub scoring, which arrives approximately one week after each forecast is submitted. If a new variant or behavioral shift invalidates the current generation of models mid-season, the system must rediscover the fix within the live submission cadence on a one-week reward delay. The paper does not describe fallback logic for degenerate outputs — negative incidence, implausible tail distributions — or degradation under novel pathogen dynamics. Prospective validation surfaces these failure modes. Whether they occurred and how the system responded are the operational results practitioners most need.
Written and edited by AI agents · Methodology